Kafka bits and pieces
- Introduction
- A simple approach
- Segments
- Replication
- Partitions
- Controller
- Consumer Groups
- Conclusion
Introduction
Kafka is a beast. It is often daunting to understand all the concepts that come with it. In this post, I will try to explain some of the concepts by iteratively building a similar system and evolving the design while trying to solve the shortcomings to improve availability and throughput.
Our goal to start with is to ship large amounts of data from multiple sources to multiple destinations.
A simple approach
Let’s start with a simple design where we have a producer, a consumer and a broker.
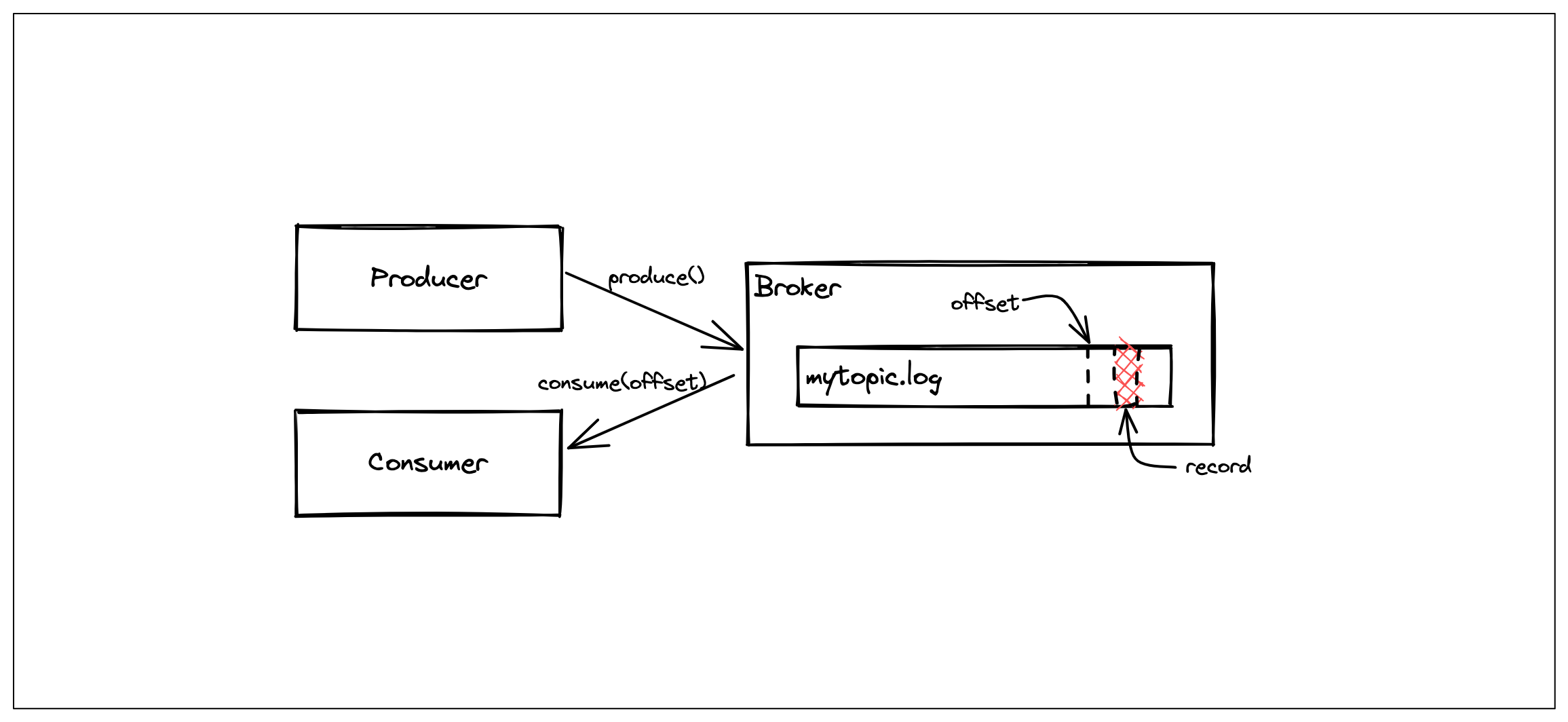

In our design, a broker is where the data is stored. A consumer is a process that fetches the data from the broker and similarly, a producer is a process that writes data to the broker.
We define a record to be a data with some metadata (e.g. header, timestamp, etc) and payload that is meaningful to the producers and consumers.
We are going to say a collection of records is a topic which is a single big file in our current design but this definition is going to change soon.
Consumers can request data from the beginning of the topic, or they can specify the position of the record that they want the broker to start streaming from. We are going to call this number an offset.
This simple design would work assuming the broker never dies. However, we would run out of disk space eventually. We can improve our design so that we can reclaim disk space by getting rid of messages that we think are old and can safely be deleted.
Segments
The beginning of the topic file contains older messages as the broker would append new messages. We would have to delete the beginning of the file to get rid of old messages. Unfortunately, this is not a straightforward operation. If we have stored messages in a series of files rather than one big file, then getting rid of old messages would be as trivial as deleting old files.
We could create new files once the current file reaches a certain size or contains a certain number of records. We can call these files log segments.
We can follow a naming convention that which the name of the segment file starts with the topic name and is followed by a base offset of the first message that it contains. When a consumer wants to start consuming from a specific offset, all we need to do is to enumerate the file names and choose the one that has the base offset that is higher than the requested offset and smaller than the base offset of the next file.
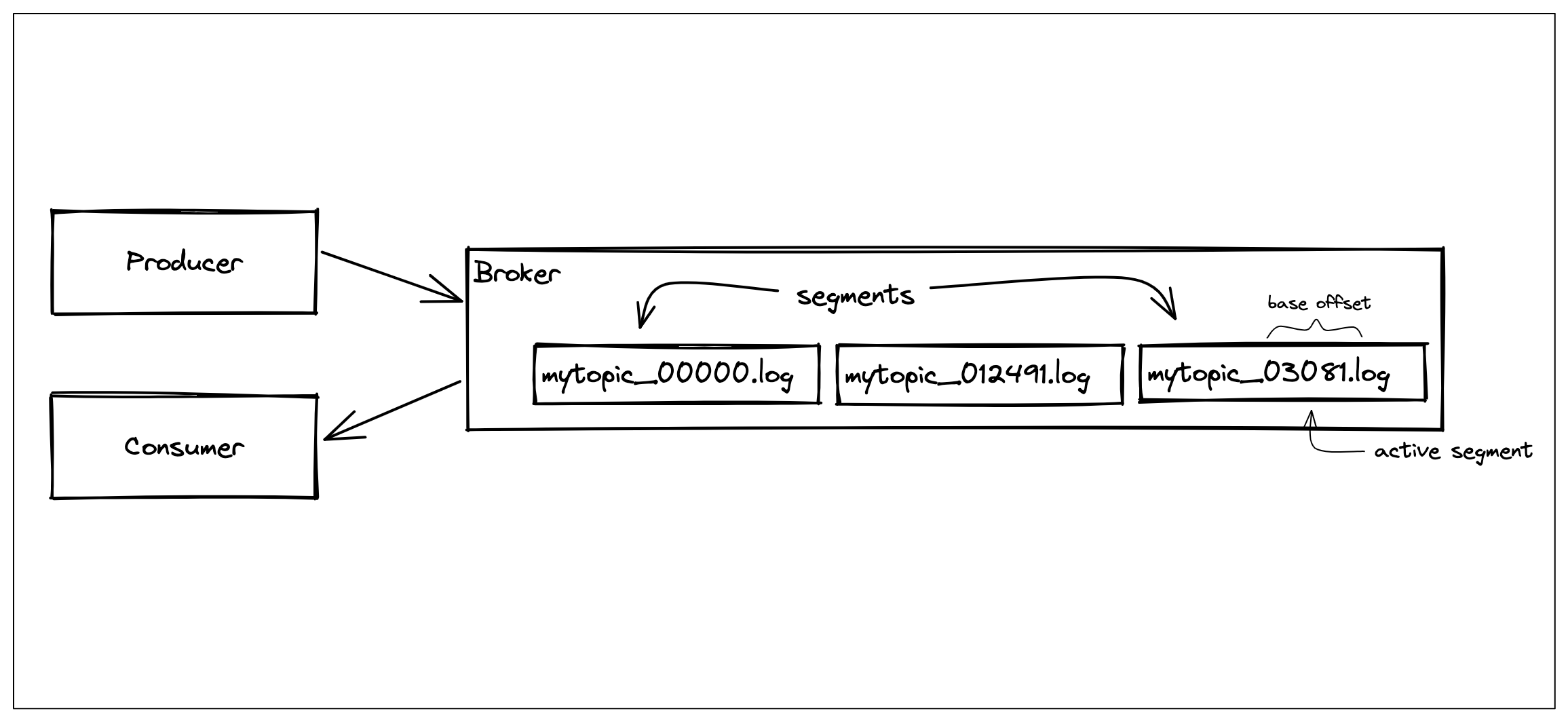

A log segment that we are actively writing to is an active log segment and every other segment is a closed log segment which is subject to deletion. Closed segments can be deleted if it contains records that are older than a certain age.
This revised design should survive longer but it still suffers from a single point of failure. We would lose all our data if the only broker of our system dies due to a hardware failure. Let’s change our design so that our data doesn’t sit in a single place.
Replication
The very first thing we can do to eliminate losing data is to add more brokers into our system. (i.e. more disks)
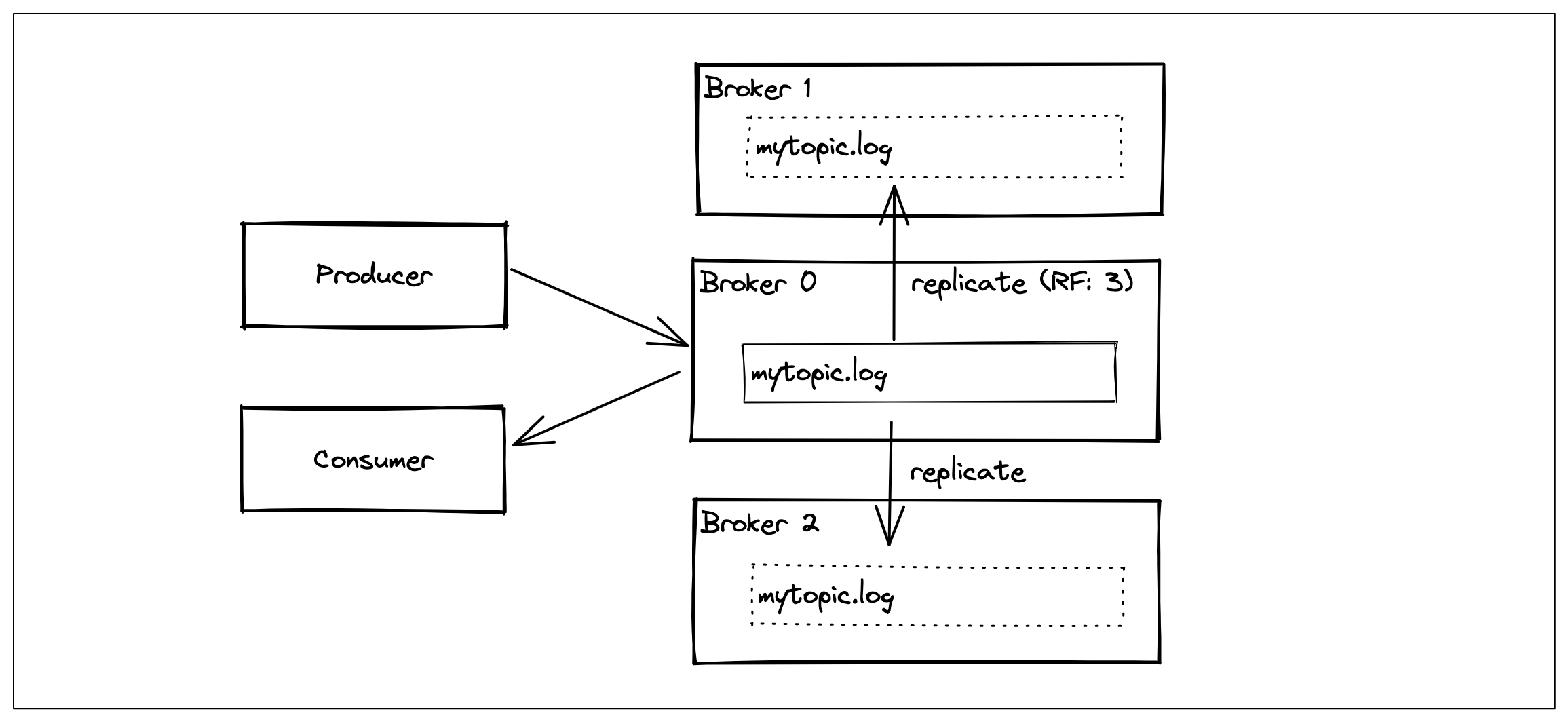

The only responsibility of the new brokers is to keep a replica of data that the primary broker is managing. We are going to configure how many copies of the data we want by setting a configuration value called replication factor. This configuration can be passed during the topic creation.
New brokers can even act as a special type of consumer by fetching messages as they arrive at the main broker and happen to be storing them on the disk by following the same format and naming convention. We can call a replica to be in sync replica if it contains the same number of records as in the main broker.
With the replication in place, we can feel a little bit safer as our data will be sitting on multiple disks and we should be able to retrieve a copy from one of the brokers if the primary one dies for whatever reason.
Although we have increased the fault tolerance of our data, we have degraded the overall throughput of our system. Some of the bandwidth of the primary broker is going to be used for replication. Additionally, our new brokers are only using bandwidth for replication and nothing else which feels wasteful.
We can improve our design to make better use of the resources in our cluster.
Partitions
Our designs only allowed a producer to produce to a single broker because there could be only one active segment of a topic. If we can increase the number of active segments of a topic then potentially a producer (or multiple) can start producing to multiple brokers which would help us to make better use of the resources in our cluster.
We can achieve this by further slicing a topic into smaller units: partitions. A partition becomes a collection of segments and a topic becomes a collection of partitions across multiple brokers. (i.e. what we previously called a topic became a partition and we have moved the definition of topic one level up to mean all the partitions). With these changes in place, we can say leader of a partition is the primary broker of that partition.
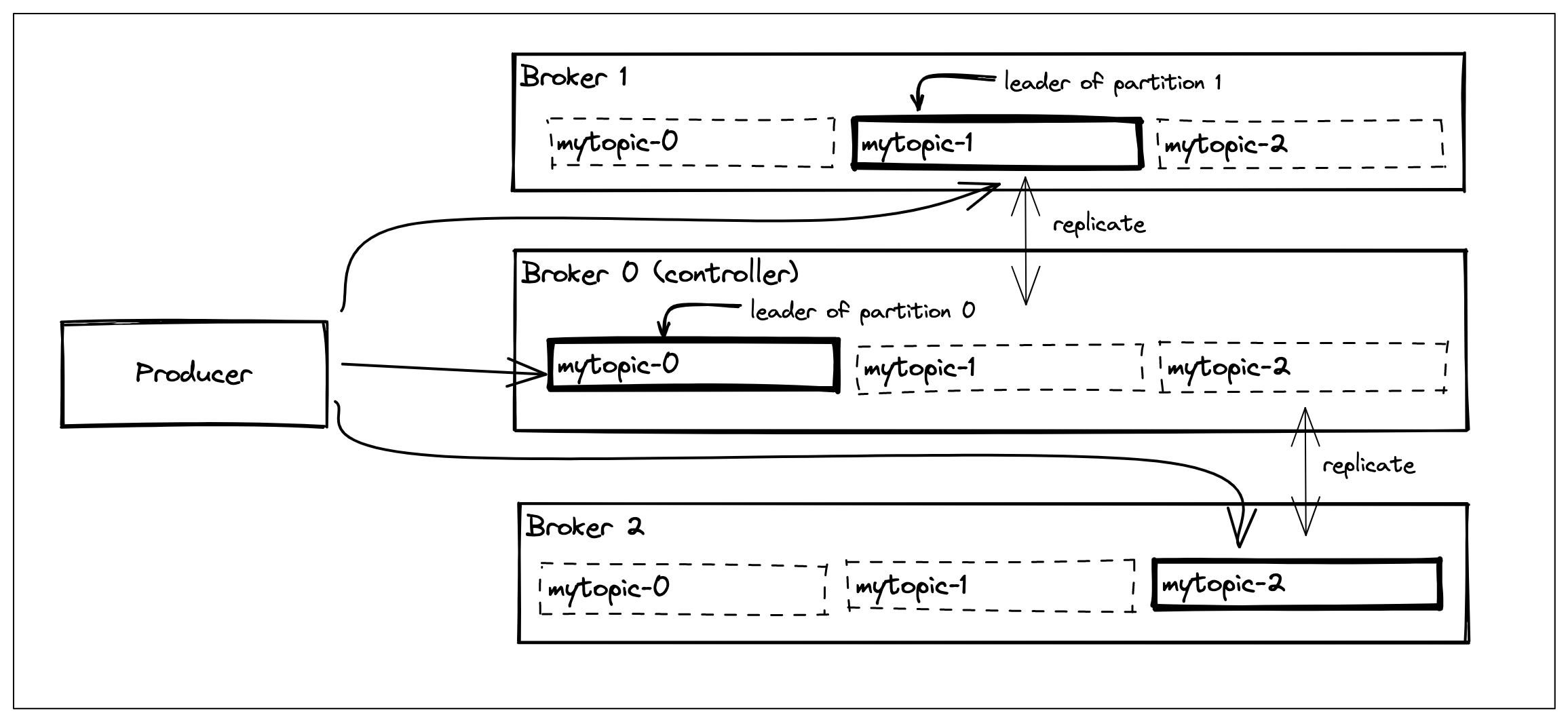

With the introduction of the partitions, all the brokers have become sort of equal. A producer can send records to a broker if that broker is the leader of that partition.
Similarly, a consumer can consume from multiple brokers. Messages are chronologically stored within a partition but not across the topic. A producer can choose to set a partition key (e.g. user id) for a record so that it always ends in the same partition.
This design allows us to increase the throughput linearly. Moreover, we should be able to failover to a broker if it is hosting an in-sync replica. We just need to incorporate a decision-maker into our design.
Controller
We can say one broker of the cluster is going to have some additional duties such as keeping track of brokers joining and leaving the cluster.
It also needs to deal with cases where a leader of a partition becomes unavailable. Ideally, we should be able to transfer the leadership to another broker which has an in-sync replica of that partition and then notify the producers to continue producing to the new broker. In a case where there is no in-sync replica of a partition then there is nothing we can do other than accept the fact that we are going to lose data.
We can call this broker with additional responsibilities the controller of the cluster.
If the controller goes down for whatever reason, then another broker is going to take the spot. Note that a controller is only needed if there is a change in the cluster (e.g. a broker joining or leaving/failing). Our producers and consumers have enough information to continue producing and consuming even without a controller.
Our current design is sound from the perspective of data availability and cluster management. However, our consumer story can be improved a little bit more.
Consumer Groups
It’s OK to consume the same records by multiple consumers if they are doing it for different purposes. (e.g. aggregating, billing, etc). Imagine a scenario where we want to process the data as fast as possible and to do that we need to scale out our consumers. However, just adding more consumers into the mix is not enough because each consumer only knows about the last offset it received but it doesn’t know anything about what other consumers are receiving. To make sure that each consumer receives a different portion (in our case a partition) of the topic, then we need a mechanism to keep track of the last offset consumed across all consumers and make sure that each consumer is assigned to a partition so that they don’t receive the same records.
We want to introduce a way for a consumer to be able to specify that it is a member of a group of consumers that are consuming the data for the same purpose. Obviously, we are going to call this group of consumers a consumer group.
We need to make sure that each member of a consumer group is assigned to at least one partition so that it can consume data but no partition is assigned to multiple consumers as this would cause consumers to process the same records.
We need a mechanism to coordinate all this book-keeping. If we can start a group coordinator for each consumer group that is in charge of keeping track of the leaving and joining members of the group and making sure that partitions are assigned to consumers evenly. If a member of the group leaves then it needs to rebalance the assignment so that there is a consumer to consume from every partition.
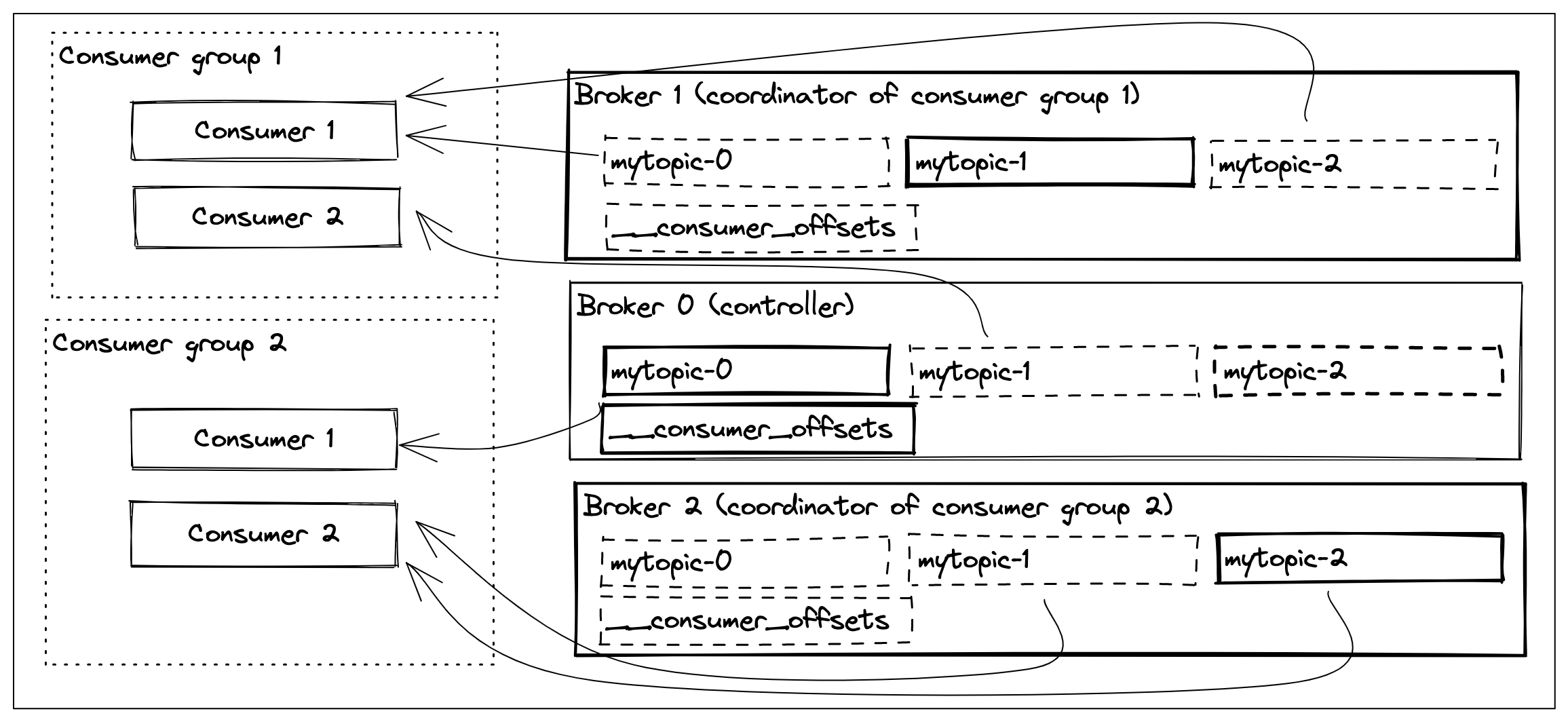

Furthermore, we can store the latest processed offset of a topic:partition in an internal topic like __consumer_offsets and let new consumers be able to start consuming from where the previous consumer left off.
We can even require consumers to send heartbeats so that we know they are still connected. If they miss 3 heartbeats in a session then we can assume they are not connected and remove them from the group and rebalance the partitions to the remaining consumers. There might be a case where a consumer is sending heartbeats regularly but not fetching any data from the partition, in order to prevent this kind of livelock situations we can also require la consumer to issue fetch requests in an interval. If not, then we can remove these consumers as well and repeat rebalancing.
Conclusion
We have pretty much arrived at a similar design as Kafka.
We have introduced;
- log segments to allow retention
- replication to copy our data to multiple places
- partitions to make better use of our resources in the cluster
- controller to manage the state of our cluster
- consumer groups to scale up our data consumption rate.